
At its Search On event today, Google introduced several new features that, taken together, are its strongest attempts yet to get people to do more than type a few words into a search box. By leveraging its new Multitask Unified Model (MUM) machine learning technology in small ways, the company hopes to kick off a virtuous cycle: it will provide more detail and context-rich answers, and in return it hopes users will ask more detailed and context-rich questions. The end result, the company hopes, will be a richer and deeper search experience.
Google SVP Prabhakar Raghavan oversees search alongside Assistant, ads, and other products. He likes to say — and repeated in an interview this past Sunday — that “search is not a solved problem.” That may be true, but the problems he and his team are trying to solve now have less to do with wrangling the web and more to do with adding context to what they find there.
For its part, Google is going to begin flexing its ability to recognize constellations of related topics using machine learning and present them to you in an organized way. A coming redesign to Google search will begin showing “Things to know” boxes that send you off to different subtopics. When there’s a section of a video that’s relevant to the general topic — even when the video as a whole is not — it will send you there. Shopping results will begin to show inventory available in nearby stores, and even clothing in different styles associated with your search.
For your part, Google is offering — though perhaps “asking” is a better term — new ways to search that go beyond the text box. It’s making an aggressive push to get its image recognition software Google Lens into more places. It will be built into the Google app on iOS and also the Chrome web browser on desktops. And with MUM, Google is hoping to get users to do more than just identify flowers or landmarks, but instead use Lens directly to ask questions and shop.
“It’s a cycle that I think will keep escalating,” Raghavan says. “More technology leads to more user affordance, leads to better expressivity for the user, and will demand more of us, technically.”
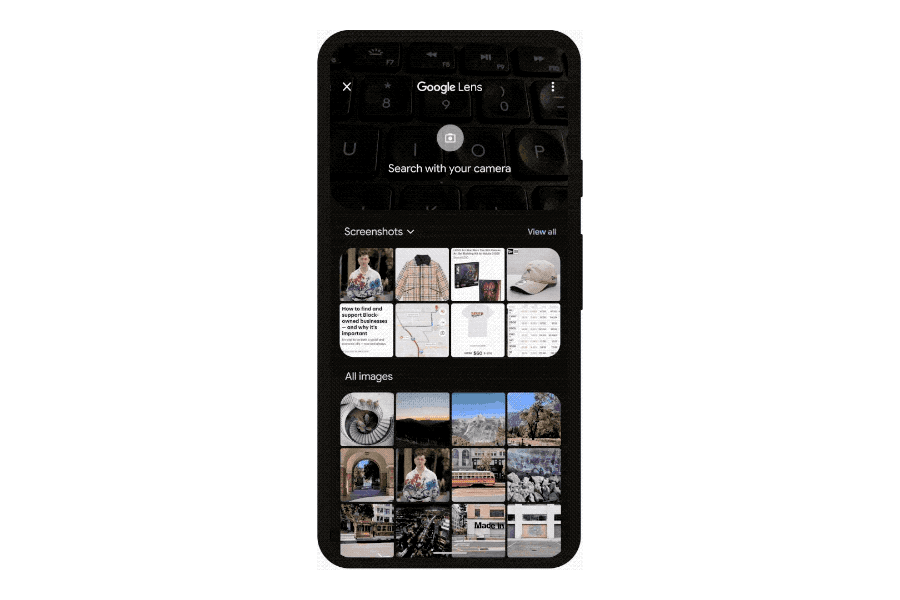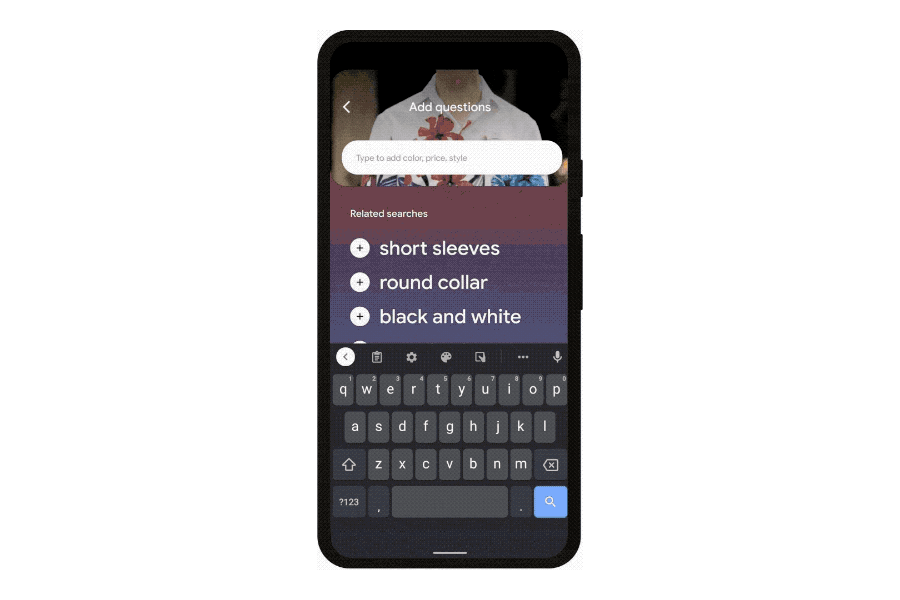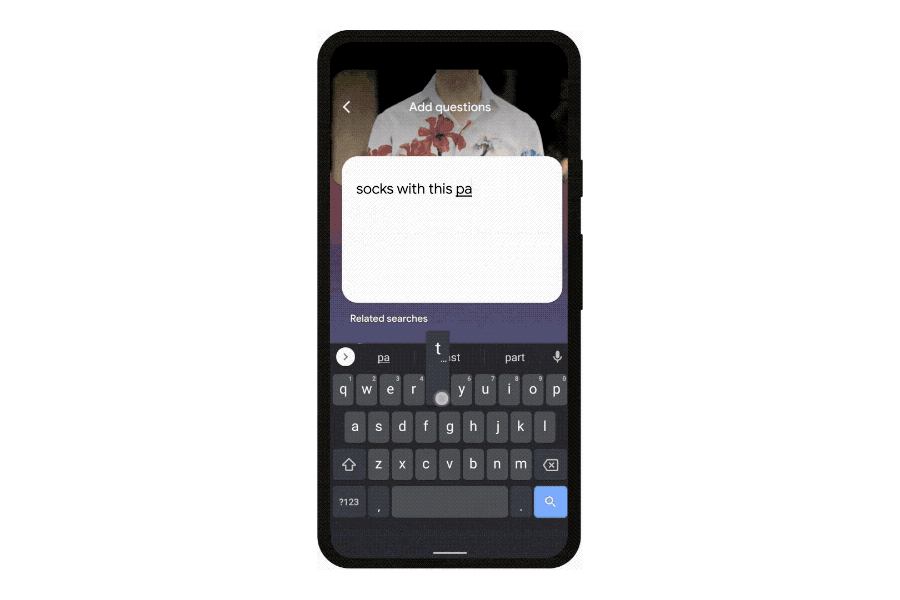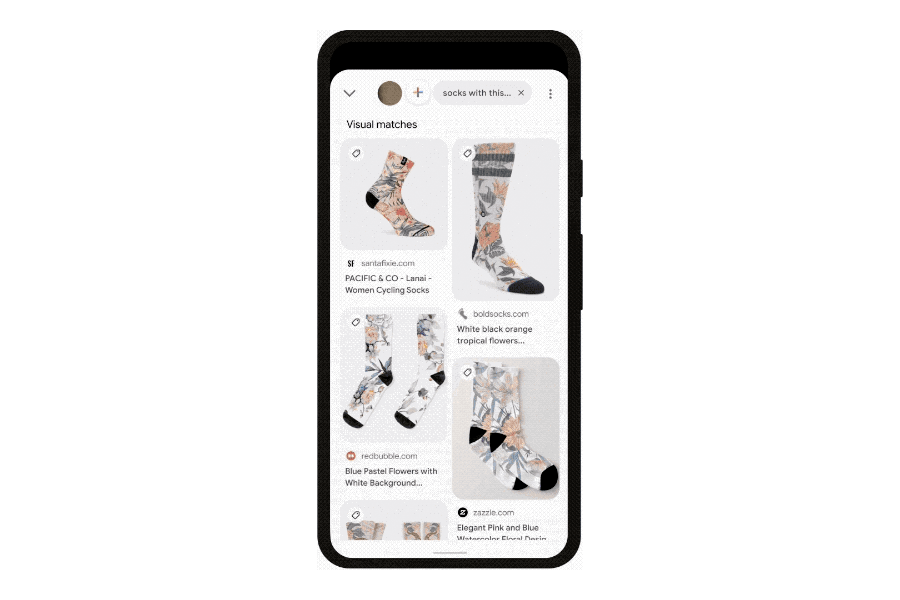
Those two sides of the search equation are meant to kick off the next stage of Google search, one where its machine learning algorithms become more prominent in the process by organizing and presenting information directly. In this, Google efforts will be helped hugely by recent advances in AI language processing. Thanks to systems known as large language models (MUM is one of these), machine learning has got much better at mapping the connections between words and topics. It’s these skills that the company is leveraging to make search not just more accurate, but more explorative and, it hopes, more helpful.
One of Google’s examples is instructive. You may not have the first idea what the parts of your bicycle are called, but if something is broken you’ll need to figure that out. Google Lens can visually identify the derailleur (the gear-changing part hanging near the rear wheel) and rather than just give you the discrete piece of information, it will allow you to ask questions about fixing that thing directly, taking you to the information (in this case, the excellent Berm Peak Youtube channel).
The push to get more users to open up Google Lens more often is fascinating on its own merits, but the bigger picture (so to speak) is about Google’s attempt to gather more context about your queries. More complicated, multimodal searches combining text and images demand “an entirely different level of contextualization that we the provider have to have, and so it helps us tremendously to have as much context as we can,” Raghavan says.
We are very far from the so-called “ten blue links” of search results that Google provides. It has been showing information boxes, image results, and direct answers for a long time now. Today’s announcements are another step, one where the information Google provides is not just a ranking of relevant information but a distillation of what its machines understand by scraping the web.
In some cases — as with shopping — that distillation means you’ll likely be sending Google more page views. As with Lens, that trend is important to keep an eye on: Google searches increasingly push you to Google’s own products. But there’s a bigger danger here, too. The fact that Google is telling you more things directly increases a burden it’s always had: to speak with less bias.
By that, I mean bias in two different senses. The first is technical: the machine learning models that Google wants to use to improve search have well-documented problems with racial and gender biases. They’re trained by reading large swaths of the web, and, as a result, tend to pick up nasty ways of talking. Google’s troubles with its AI ethics team are also well documented at this point — it fired two lead researchers after they published a paper on this very subject. As Google’s VP of search, Pandu Nayak, told The Verge’s James Vincent in his article on today’s MUM announcements, Google knows that all language models have biases, but the company believes it can avoid “putting it out for people to consume directly.”

Be that as it may (and to be clear, it may not be), it sidesteps another consequential question and another type of bias. As Google begins telling you more of its own syntheses of information directly, what is the point of view from which it’s speaking? As journalists, we often talk about how the so-called “view from nowhere” is an inadequate way to present our reporting. What is Google’s point of view? This is an issue the company has confronted in the past, sometimes known as the “one true answer” problem. When Google tries to give people short, definitive answers using automated systems, it often ends up spreading bad information.
Presented with that question, Raghavan responds by pointing to the complexity of modern language models. “Almost all language models, if you look at them, are embeddings in a high dimension space. There are certain parts of these spaces that tend to be more authoritative, certain portions that are less authoritative. We can mechanically assess those things pretty easily,” he explains. Raghavan says the challenge is then how to present some of that complexity to the user without overwhelming them.
But I get the sense that the real answer is that, for now at least, Google is doing what it can to avoid facing the question of its search engine’s point of view by avoiding the domains where it could be accused of, as Raghavan puts it, “excessive editorializing.” Often when speaking to Google executives about these problems of bias and trust, they focus on easier-to-define parts of those high-dimension spaces like “authoritativeness.”
For example, Google’s new “Things to know” boxes won’t appear when somebody searches for things Google has identified as “particularly harmful/sensitive,” though a spokesperson says that Google is not “allowing or disallowing specific curated categories, but our systems are able to scalably understand topics for which these types of features should or should not trigger.”
Google search, its inputs, outputs, algorithms, and language models have all become almost unimaginably complex. When Google tells us that it is able to understand the contents of videos now, we take for granted that it has the computing chops to pull that off — but the reality is that even just indexing such a massive corpus is a monumental task that dwarfs the original mission of indexing the early web. (Google is only indexing audio transcripts of a subset of YouTube, for the record, though with MUM it aims to do visual indexing and other video platforms in the future).
Often when you’re speaking to computer scientists, the traveling salesman problem will come up. It’s a famous conundrum where you attempt to calculate the shortest possible route between a given number of cities, but it’s also a rich metaphor for thinking through how computers do their machinations.
“If you gave me all the machines in the world, I could solve fairly big instances,” Raghavan says. But for search, he says that it is unsolved and perhaps unsolvable by just throwing more computers at it. Instead, Google needs to come up with new approaches, like MUM, that take better advantage of the resources Google can realistically create. “If you gave me all the machines there were, I’m still bounded by human curiosity and cognition.”
Google’s new ways of understanding information are impressive, but the challenge is what it will do with the information and how it will present it. The funny thing about the traveling salesman problem is that nobody seems to stop and ask what exactly is in the case, what is he showing all his customers as he goes door to door?


